
Attributes and Methods of Series and Data Frames#
On the previous pages we
have seen how Pandas Series are constructed by combining Numpy arrays (the
.values attribute of a Series) with other attributes (a .name string and
array-like .index). We then examined how Pandas Data Frames are built from
a collection of Series, in a dictionary-like structure.
This page will dive deeper into the machinery behind Series and Data Frames. Once we have constructed our Series or Data Frame, Pandas provides many useful methods for cleaning, aggregating, plotting and (subsequently) analysing our data.
We will begin by showing that Pandas Series and Data Frames have many methods that parallel those of Numpy arrays, though the methods are adapted to work in the context of Pandas objects.
More Pandas from Numpy#
Let’s examine some of the methods we can use on numpy arrays.
Remember, a method is a function attached to an object.
In this case, our object is a Numpy array (later it will be a Pandas Series or Data Frame).
We’ll build a Numpy array using the np.array([]) constructor, containing our
familiar three-letter country codes. As before, you can see the datasets and
licenses page for more detail.
# Import libraries
import numpy as np
import pandas as pd
# Our own routine to giving hints to the exercises.
from hint import hint_1, hint_2
We build the constituent arrays:
# Standard three-letter code for each country
country_codes_array = np.array(['AUS', 'BRA', 'CAN',
'CHN', 'DEU', 'ESP',
'FRA', 'GBR', 'IND',
'ITA', 'JPN', 'KOR',
'MEX', 'RUS', 'USA'])
# Human Development Index Scores for each country
hdis_array = np.array([0.896, 0.668, 0.89,
0.586, 0.89, 0.828,
0.844, 0.863, 0.49,
0.842, 0.883, 0.824,
0.709, 0.733, 0.894])
# Full names of each country.
country_names_array = np.array(['Australia', 'Brazil', 'Canada',
'China', 'Germany', 'Spain',
'France', 'United Kingdom', 'India',
'Italy', 'Japan', 'South Korea',
'Mexico', 'Russia', 'United States'])
When dealing with any object in Python, it can be useful to use the in-built
Python dir() function. This returns the names of every attribute and
method that we can access/call from the object:
# Show all available attributes/methods
dir(hdis_array)
['T',
'__abs__',
'__add__',
'__and__',
'__array__',
'__array_finalize__',
'__array_function__',
'__array_interface__',
'__array_namespace__',
'__array_priority__',
'__array_struct__',
'__array_ufunc__',
'__array_wrap__',
'__bool__',
'__buffer__',
'__class__',
'__class_getitem__',
'__complex__',
'__contains__',
'__copy__',
'__deepcopy__',
'__delattr__',
'__delitem__',
'__dir__',
'__divmod__',
'__dlpack__',
'__dlpack_device__',
'__doc__',
'__eq__',
'__float__',
'__floordiv__',
'__format__',
'__ge__',
'__getattribute__',
'__getitem__',
'__getstate__',
'__gt__',
'__hash__',
'__iadd__',
'__iand__',
'__ifloordiv__',
'__ilshift__',
'__imatmul__',
'__imod__',
'__imul__',
'__index__',
'__init__',
'__init_subclass__',
'__int__',
'__invert__',
'__ior__',
'__ipow__',
'__irshift__',
'__isub__',
'__iter__',
'__itruediv__',
'__ixor__',
'__le__',
'__len__',
'__lshift__',
'__lt__',
'__matmul__',
'__mod__',
'__mul__',
'__ne__',
'__neg__',
'__new__',
'__or__',
'__pos__',
'__pow__',
'__radd__',
'__rand__',
'__rdivmod__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rfloordiv__',
'__rlshift__',
'__rmatmul__',
'__rmod__',
'__rmul__',
'__ror__',
'__rpow__',
'__rrshift__',
'__rshift__',
'__rsub__',
'__rtruediv__',
'__rxor__',
'__setattr__',
'__setitem__',
'__setstate__',
'__sizeof__',
'__str__',
'__sub__',
'__subclasshook__',
'__truediv__',
'__xor__',
'all',
'any',
'argmax',
'argmin',
'argpartition',
'argsort',
'astype',
'base',
'byteswap',
'choose',
'clip',
'compress',
'conj',
'conjugate',
'copy',
'ctypes',
'cumprod',
'cumsum',
'data',
'device',
'diagonal',
'dot',
'dtype',
'dump',
'dumps',
'fill',
'flags',
'flat',
'flatten',
'getfield',
'imag',
'item',
'itemsize',
'mT',
'max',
'mean',
'min',
'nbytes',
'ndim',
'nonzero',
'partition',
'prod',
'put',
'ravel',
'real',
'repeat',
'reshape',
'resize',
'round',
'searchsorted',
'setfield',
'setflags',
'shape',
'size',
'sort',
'squeeze',
'std',
'strides',
'sum',
'swapaxes',
'take',
'to_device',
'tobytes',
'tofile',
'tolist',
'trace',
'transpose',
'var',
'view']
For now we will ignore the elements in the printout that contain __. These
double underscores are called “dunders” (short for double underscores);
attributes and methods starting and ending with __ are often called dunder
attributes and dunder methods. Python uses the dunder naming scheme as
a convention to indicate that these methods and attributes are part of the
internal machinery of an object.
Another Python naming convention uses an underscore _ at the start of
a method or attribute name to indicate that the method or attribute is
private — that is, the attribute / method is for the object to use, but for
us — the user of the object — to avoid.
Ignoring the all attributes and methods that begin with underscores, we can see a large number of attributes and methods that we can access from this or any other Numpy array.
# Attributes and methods not starting with `_` (or `__`):
[k for k in dir(hdis_array) if not k.startswith('_')]
['T',
'all',
'any',
'argmax',
'argmin',
'argpartition',
'argsort',
'astype',
'base',
'byteswap',
'choose',
'clip',
'compress',
'conj',
'conjugate',
'copy',
'ctypes',
'cumprod',
'cumsum',
'data',
'device',
'diagonal',
'dot',
'dtype',
'dump',
'dumps',
'fill',
'flags',
'flat',
'flatten',
'getfield',
'imag',
'item',
'itemsize',
'mT',
'max',
'mean',
'min',
'nbytes',
'ndim',
'nonzero',
'partition',
'prod',
'put',
'ravel',
'real',
'repeat',
'reshape',
'resize',
'round',
'searchsorted',
'setfield',
'setflags',
'shape',
'size',
'sort',
'squeeze',
'std',
'strides',
'sum',
'swapaxes',
'take',
'to_device',
'tobytes',
'tofile',
'tolist',
'trace',
'transpose',
'var',
'view']
One of these array attributes is shape. We often want to know the shape of our data, as it tells us the number of elements along each dimension (axis) of the array:
# Shape
hdis_array.shape
(15,)
We can read this output as “15 elements in a single dimension”. By contrast, let’s look at an array with more than one dimension:
# Arrays with more dimensions
zeros_array = np.zeros([2, 2])
zeros_array
array([[0., 0.],
[0., 0.]])
This 2D array has the following shape:
# Arrays with more dimensions
zeros_array.shape
(2, 2)
We an read this as “2 rows and 2 columns” (which equates to 4 elements), or “two elements along the first dimension, two elements along the second”.
If we want to count the number of individual elements in an array (across all dimensions) we can use the .size attribute:
# How many elements in the (15, ) `hdi` array?
hdis_array.size
15
# How many elements in the (2, 2) `zeros_array`?
zeros_array.size
4
len() as applied to Numpy arrays gives us the number of elements of the first dimension (axis) only.
len(zeros_array)
2
len(hdis_array)
15
Note
How does len() work?
Calling the standard Python function len() on an object obj causes Python to call the __len__() method of the object. Therefore, the result of len(obj) is the same as that for obj.__len__().
Each object type can define what len(obj) means by implementing a __len__
method. For Numpy arrays arr.__len__() gives you the equivalent of
arr.shape[0].
Later we will see that Data Frames have their own implementation of __len__.
We also often want to know the type of data in our array, as it will affect the analyses we can perform. Are we dealing with numbers or text, for instance?
To access this information, we can view the dtype attribute.
Let’s look at the dtype for the country_codes array:
# Dtype
country_codes_array.dtype
dtype('<U3')
The dtype attribute tells us that this is string data. For an explanation of
the meaning, see the image below.
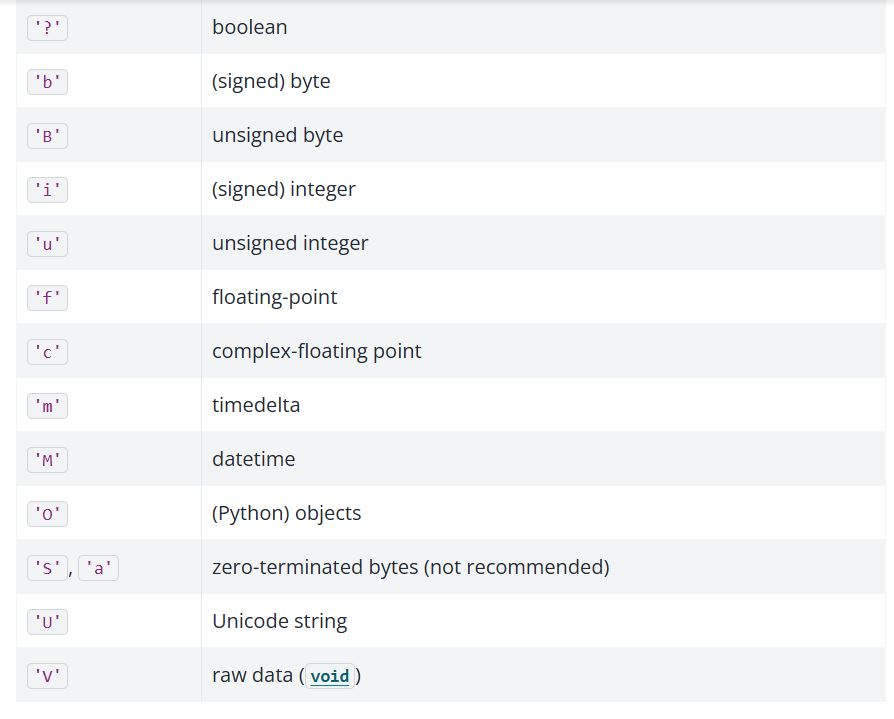
Let’s look at the dtype of the hdis_array:
# Dtype (again)
hdis_array.dtype
dtype('float64')
For this array, the dtype tells us that we are dealing with numerical data - specifically float data represented with 64 bits of memory per element.
Statistical Attributes of Numpy arrays#
Numpy also provides a variety of what we can call “statistical attributes” which tell us statistics about the data inside the array.
Note
What is a statistic?
A statistic is some number or sequence of numbers that summarizes a distribution of values. For example, the mean or average is a measure of the center of the distribution. Similarly the min and max are the values on the extreme left and extreme right of a distribution.
As with the methods we looked at in the previous section, Pandas has its own versions of many of these methods, as we will see later in the page.
Let’s again look at the hdis_array, which contains the HDI score of each country.
hdis_array
array([0.896, 0.668, 0.89 , 0.586, 0.89 , 0.828, 0.844, 0.863, 0.49 ,
0.842, 0.883, 0.824, 0.709, 0.733, 0.894])
There are a variety of useful statistical methods for arrays:
# Minimum value in entire array.
hdis_array.min()
np.float64(0.49)
# Maximum value in entire array.
hdis_array.max()
np.float64(0.896)
# Mean of all values in array.
hdis_array.mean()
np.float64(0.7893333333333333)
# Standard deviation.
hdis_array.std()
np.float64(0.12125821850726472)
Pandas Series attributes and methods#
Remember our answer to What is a Series?:
A Series is the association of:
An array of values (
.values)A sequence of labels for each value (
.index)A name (which can be
None).
Because Series have arrays as their underlying model for storing values, it is not surprising that we can use many of the same methods we have just seen for Numpy arrays on Pandas Series.
Let’s make a series from the HDI scores, called hdi_series. We do this using the now familiar pd.Series() constructor. Again, we will use the country_codes array as an index:
# Show again from Series, then show for df below
hdi_series = pd.Series(hdis_array,
index=country_codes_array)
hdi_series
AUS 0.896
BRA 0.668
CAN 0.890
CHN 0.586
DEU 0.890
ESP 0.828
FRA 0.844
GBR 0.863
IND 0.490
ITA 0.842
JPN 0.883
KOR 0.824
MEX 0.709
RUS 0.733
USA 0.894
dtype: float64
As we know, we can view the index, name and values attributes of the Series using the familiar accessors:
# The `index` component of the Series
hdi_series.index
Index(['AUS', 'BRA', 'CAN', 'CHN', 'DEU', 'ESP', 'FRA', 'GBR', 'IND', 'ITA',
'JPN', 'KOR', 'MEX', 'RUS', 'USA'],
dtype='str')
# The `name` component (currently is None)
hdi_series.name is None
True
# The numpy array (aka `.values`) component of the Series
hdi_series.values
array([0.896, 0.668, 0.89 , 0.586, 0.89 , 0.828, 0.844, 0.863, 0.49 ,
0.842, 0.883, 0.824, 0.709, 0.733, 0.894])
Let’s verify that we can use methods that parallel the Numpy methods we saw above. Predictably, these methods operate on the Numpy array component of the series (e.g. the .values attribute).
First, let’s look at the shape, size and dtype:
# Show the `shape` of the `hdi_series`
hdi_series.shape
(15,)
# Show the `size` of the `hdi_series`
hdi_series.size
15
# Show the `dtype` of the `hdi_series`
hdi_series.dtype
dtype('float64')
Because a Series is a Numpy array (of .values) plus some additional
attributes/methods, these methods work on the Series in a very similar manner
to their equivalents on Numpy arrays.
This also applies to statistical methods. Let’s get the .min() and .max() values from the hdi_series.
# Min
hdi_series.min()
np.float64(0.49)
# Max
hdi_series.max()
np.float64(0.896)
These operations return the same values as when we call the method directly on the hdis_array (unsurprising, as each object contains the same data)!:
# Get the `max()` value from the `hdis_array`, for comparison
hdis_array.max()
np.float64(0.896)
Ok, so these methods are available with names that are familiar from Numpy.
However, Pandas also introduces some additional methods. You may want to
compare the output of dir() for the hdis_array vs the hdi_series to see
the overlap/differences - as the printout is messy, we will not show it again
here.
One very useful Series method is .describe(). This will give us a variety of
statistics about the data in the .values array of the Series:
# Use the `.describe()` on the `hdi_series`
hdi_series.describe()
count 15.000000
mean 0.789333
std 0.125514
min 0.490000
25% 0.721000
50% 0.842000
75% 0.886500
max 0.896000
dtype: float64
Neat, an easy summary of the number of observations, the mean, the standard deviation around the mean, and then the range/interquartile range.
Conversely, the .value_counts() method will count the occurrence of each unique value in the Series:
# Use the `value_counts()` method
hdi_series.value_counts()
0.890 2
0.896 1
0.668 1
0.586 1
0.828 1
0.844 1
0.863 1
0.490 1
0.842 1
0.883 1
0.824 1
0.709 1
0.733 1
0.894 1
Name: count, dtype: int64
These methods can also be applied to arrays containing categorical/string data:
# Constructing a Series containing categorical data
country_names_series = pd.Series(country_names_array,
index=country_codes_array)
country_names_series
AUS Australia
BRA Brazil
CAN Canada
CHN China
DEU Germany
ESP Spain
FRA France
GBR United Kingdom
IND India
ITA Italy
JPN Japan
KOR South Korea
MEX Mexico
RUS Russia
USA United States
dtype: str
# Using .describe()
country_names_series.describe()
count 15
unique 15
top Australia
freq 1
dtype: object
Helpfully, Pandas has adjusted the .describe() summary in light of the
values array of the country_names_series containing categorical/string
data.
We now see summaries of the number of values, number of unique values etc, rather than numerical statistics like the mean and standard deviation.
The .value_counts() method behaves the same as with numerical data, as both
numbers and strings can be unique in an array. For our case, the output isn’t very interesting, as all the country names are unique.
country_names_series.value_counts()
Australia 1
Brazil 1
Canada 1
China 1
Germany 1
Spain 1
France 1
United Kingdom 1
India 1
Italy 1
Japan 1
South Korea 1
Mexico 1
Russia 1
United States 1
Name: count, dtype: int64
If we want to see the unique values only, regardless of the number of times
each value occurs, we can use the .unique() method. This gives us an array
of the unique values.
# Show the unique values in the Series
hdi_series.unique()
array([0.896, 0.668, 0.89 , 0.586, 0.828, 0.844, 0.863, 0.49 , 0.842,
0.883, 0.824, 0.709, 0.733, 0.894])
# Show the unique values in the Series
country_names_series.unique()
<StringArray>
[ 'Australia', 'Brazil', 'Canada', 'China',
'Germany', 'Spain', 'France', 'United Kingdom',
'India', 'Italy', 'Japan', 'South Korea',
'Mexico', 'Russia', 'United States']
Length: 15, dtype: str
# But of course, all the country names are unique, so the
# above is the same, in our case, as:
country_names_series.values
<StringArray>
[ 'Australia', 'Brazil', 'Canada', 'China',
'Germany', 'Spain', 'France', 'United Kingdom',
'India', 'Italy', 'Japan', 'South Korea',
'Mexico', 'Russia', 'United States']
Length: 15, dtype: str
Pandas Data Frame attributes#
Now, remember again our other maxim that A Data Frame is a dictionary-like collection of Series.
Because of this, we can use all the methods we have seen so far on any Data Frame column. Each column is a Series, and therefore contains a Numpy array as its .values attribute.
However, Data Frames have some (useful!) extra methods (including statistical methods) not available for Series.
First, let’s import the HDI/fertility rate data:
# Import our dataset
df = pd.read_csv("data/year_2000_hdi_fert.csv")
df
| Code | Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|---|
| 0 | AUS | 0.896 | 1.764 | 19.1324 | Australia |
| 1 | BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| 2 | CAN | 0.890 | 1.510 | 30.8918 | Canada |
| 3 | CHN | 0.586 | 1.628 | 1269.5811 | China |
| 4 | DEU | 0.890 | 1.386 | 81.7972 | Germany |
| 5 | ESP | 0.828 | 1.210 | 41.0197 | Spain |
| 6 | FRA | 0.844 | 1.876 | 59.4837 | France |
| 7 | GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| 8 | IND | 0.490 | 3.350 | 1057.9227 | India |
| 9 | ITA | 0.842 | 1.249 | 57.2722 | Italy |
| 10 | JPN | 0.883 | 1.346 | 127.0278 | Japan |
| 11 | KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| 12 | MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| 13 | RUS | 0.733 | 1.190 | 146.7177 | Russia |
| 14 | USA | 0.894 | 2.030 | 281.4841 | United States |
We can use dir() on this Data Frame, to view all of the available
attributes and methods (that don’t begin with _):
# Show all available operations on the dataframe
[k for k in dir(df) if not k.startswith('_')]
['Code',
'Population',
'T',
'abs',
'add',
'add_prefix',
'add_suffix',
'agg',
'aggregate',
'align',
'all',
'any',
'apply',
'asfreq',
'asof',
'assign',
'astype',
'at',
'at_time',
'attrs',
'axes',
'between_time',
'bfill',
'boxplot',
'clip',
'columns',
'combine',
'combine_first',
'compare',
'convert_dtypes',
'copy',
'corr',
'corrwith',
'count',
'cov',
'cummax',
'cummin',
'cumprod',
'cumsum',
'describe',
'diff',
'div',
'divide',
'dot',
'drop',
'drop_duplicates',
'droplevel',
'dropna',
'dtypes',
'duplicated',
'empty',
'eq',
'equals',
'eval',
'ewm',
'expanding',
'explode',
'ffill',
'fillna',
'filter',
'first_valid_index',
'flags',
'floordiv',
'from_arrow',
'from_dict',
'from_records',
'ge',
'get',
'groupby',
'gt',
'head',
'hist',
'iat',
'idxmax',
'idxmin',
'iloc',
'index',
'infer_objects',
'info',
'insert',
'interpolate',
'isetitem',
'isin',
'isna',
'isnull',
'items',
'iterrows',
'itertuples',
'join',
'keys',
'kurt',
'kurtosis',
'last_valid_index',
'le',
'loc',
'lt',
'map',
'mask',
'max',
'mean',
'median',
'melt',
'memory_usage',
'merge',
'min',
'mod',
'mode',
'mul',
'multiply',
'ndim',
'ne',
'nlargest',
'notna',
'notnull',
'nsmallest',
'nunique',
'pct_change',
'pipe',
'pivot',
'pivot_table',
'plot',
'pop',
'pow',
'prod',
'product',
'quantile',
'query',
'radd',
'rank',
'rdiv',
'reindex',
'reindex_like',
'rename',
'rename_axis',
'reorder_levels',
'replace',
'resample',
'reset_index',
'rfloordiv',
'rmod',
'rmul',
'rolling',
'round',
'rpow',
'rsub',
'rtruediv',
'sample',
'select_dtypes',
'sem',
'set_axis',
'set_flags',
'set_index',
'shape',
'shift',
'size',
'skew',
'sort_index',
'sort_values',
'squeeze',
'stack',
'std',
'style',
'sub',
'subtract',
'sum',
'swaplevel',
'tail',
'take',
'to_clipboard',
'to_csv',
'to_dict',
'to_excel',
'to_feather',
'to_hdf',
'to_html',
'to_iceberg',
'to_json',
'to_latex',
'to_markdown',
'to_numpy',
'to_orc',
'to_parquet',
'to_period',
'to_pickle',
'to_records',
'to_sql',
'to_stata',
'to_string',
'to_timestamp',
'to_xarray',
'to_xml',
'transform',
'transpose',
'truediv',
'truncate',
'tz_convert',
'tz_localize',
'unstack',
'update',
'value_counts',
'values',
'var',
'where',
'xs']
If you peruse the list you’ll notice that some of the methods have the sames as methods that apply to both Numpy arrays and Series. For instance, we can retrieve the .shape of the entire Data Frame. This gives us the number of rows and the number of columns.
# Get the shape attribute (n_rows, n_columns)
df.shape
(15, 5)
len(df) (therefore, df.__len__()) gives the number of rows. This
corresponds to the Numpy behavior of giving the number of elements on the
first dimension of the array:
# Length of Data Frame is number of rows.
len(df)
15
We can also pull out an individual Series/column and view the .shape of that specific Series:
# View the `shape` of a specific column
df['Fertility Rate'].shape
(15,)
When accessed for the entire Data Frame, the size attribute works in the same way as we have seen for Numpy arrays and Pandas Series e.g. it will tell us the total number of elements in the entire Data Frame (e.g. the number of elements in the rows multiplied by the number of elements in the columns):
# Show the `size` of the Data Frame
df.size
75
Exercise 5
Your job here is to make a new Series which summarises aspects of the df Data Frame. In the .values array, your Series should contain the values of the .shape and .size attributes of df. It should also contain the dtype of the index of df (therefore, telling your user whether the index contains numeric labels, str labels, or something else). See if you can figure out how to get Pandas to report this via indexing (e.g. rather than copy pasting the information from the output of df.index).
The index of your Series should clearly state what each value is. E.g. the strings shape, size, index_dtype should be the index labels in your Series.
The name attribute of your Series should bedf_attributes.
When displayed, your Series should look like this:
shape (15, 4)
size 60
index_dtype int64
Name: df_attributes, dtype: object
Try to create this Series in as few lines of code as possible.
You may run into an error with the shape attribute. Try running hint_1() for a hint on how to solve this.
You can also run hint_2() to get a hint on how to get Pandas to report the dtype of the index.
Try to use the hints as a last resort, however…
# Your code here
Solution to Exercise 5
Our solution to this is below. First, we create an array containing the attributes. We must use the str() function to convert the output of df.shape to a single dimension (a str with 7 characters, rather than a (2, ) tuple). This is in order to make its shape match that of df.size and the index.dtype string. Otherwise we get a nasty error when passing the array to the pd.Series() constructor, because we are trying to make a .values array using values with incompatible dimensions.
We got the dtype of the index labels by accessing the dtype attribute of the index, in a chained operation e.g.: df.index.dtype.
We set the index and the name when we call the as optional arguments within pd.Series() (you may have done this using df.index = and df.name =, which is another valid approach):
# Make an array containing the desired attributes - note the use of `str()`
attributes_array = np.array([str(df.shape),
df.size,
df.index.dtype])
# Convert to Series, specify `index` and `name`
df_attributes = pd.Series(attributes_array,
index = ['shape', 'size', "index_dtype"],
name = "df_attributes" )
# Show the Series
df_attributes
shape (15, 5)
size 75
index_dtype int64
Name: df_attributes, dtype: object
Creating your own Series in this way (perhaps performed by a custom function) can be useful for displaying bespoke summaries of a dataset/Data Frame. However, normally this would be done with more complicated statistical information, not just the shape/size/dtype!
Once we’ve done these preliminary inspections and we know how many observations we have, in any data analysis context, we will always want to know what variables we have in the Data Frame columns, and (again) what type of data is in each.
The .columns attribute will tell us the name (label) for each column:
# Show the column names
df.columns
Index(['Code', 'Human Development Index', 'Fertility Rate', 'Population',
'Country Name'],
dtype='str')
…and we can use the .dtypes attribute to inspect the type of data in each column:
# Show the dtype in each column
df.dtypes
Code str
Human Development Index float64
Fertility Rate float64
Population float64
Country Name str
dtype: object
Note
Strings in Pandas 2 and 3
The exact output from df.dtypes above will differ depending on your Pandas
version.
If you have Pandas version 3 or greater, you will see that the Code and
Country Name columns have data type str — a special Pandas data type to
contain strings.
If you have a Pandas version less than 3, Code and Country Name have data type object — a generic Pandas column data type that can contain any Python object.
The numeric data in this Data Frame is represented as a 64-bit float
(float64).
Now we know how much data we have, and what type of data it is. Currently, if
we want to access a specific row of the Data Frame (remember, each row here is
one country), we will have to index either by position, or by using the labels from the default RangeIndex. We did not
specify an index when we loaded in the Data Frame, so, as we learned
previously, Pandas will automatically supply one:
# Show the index (representing the integers 0 through 14)
df.index
RangeIndex(start=0, stop=15, step=1)
We have already discussed the downsides of using the default (integer) index. As we have seen before, we can use the .set_index() method to choose a column containing values which we will use as index labels. We have come across Data Frame methods previously (.sort_values()) and will look at more in the next section. For now, just remember that methods differ from data attributes in that they are a function attached to an object rather than just a value attached to an object. Methods often do something to or with the data rather than just report a value or set of values, like an attribute does.
Let’s set the Code column (containing the three-letter country codes) to be our index labels:
# Set the index as country name
df = df.set_index("Code")
df
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
As expected, when we now view the index attribute, we see that the country codes are the values that populate the index:
# Show that the index is now country names
df.index
Index(['AUS', 'BRA', 'CAN', 'CHN', 'DEU', 'ESP', 'FRA', 'GBR', 'IND', 'ITA',
'JPN', 'KOR', 'MEX', 'RUS', 'USA'],
dtype='str', name='Code')
…and we can use the now familiar (and less error-prone) label-based indexing with strings to retrieve specific rows:
# Remember what having the codes in the index lets us do
df.loc[['USA', 'ITA']]
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| USA | 0.894 | 2.030 | 281.4841 | United States |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
Pandas Data Frame methods#
The .sort_values() method we used on the previous page and the set_index() method we just used in the last section are just some of the many methods attached to Pandas Data Frames. We saw that many Numpy array methods have parallel versions that apply to Pandas Series and this principle also applies to Data Frames, built as they are from Pandas Series.
Many Data Frame methods will report information from the Data Frame as a whole, rather than just for a given column/Series.
For instance, remember the .describe() method for a Series. Here we pull out a column from the Data Frame with direct indexing, and then call .describe() on that Series.
# Pull the HDI column out of the Data Frame with direct indexing.
hdi_from_df = df['Human Development Index']
# The result is a Series, on which we can call the Series
# `.describe()` method.
hdi_from_df.describe()
count 15.000000
mean 0.789333
std 0.125514
min 0.490000
25% 0.721000
50% 0.842000
75% 0.886500
max 0.896000
Name: Human Development Index, dtype: float64
We can also call the .describe() method on the whole Data Frame. The same useful statistical summary is shown for every column when we use the method on the whole Data Frame:
# Describe numerical variables
df.describe()
| Human Development Index | Fertility Rate | Population | |
|---|---|---|---|
| count | 15.000000 | 15.000000 | 15.000000 |
| mean | 0.789333 | 1.773867 | 236.719867 |
| std | 0.125514 | 0.605841 | 384.483326 |
| min | 0.490000 | 1.190000 | 19.132400 |
| 25% | 0.721000 | 1.366000 | 52.019400 |
| 50% | 0.842000 | 1.628000 | 81.797200 |
| 75% | 0.886500 | 1.953000 | 160.367950 |
| max | 0.896000 | 3.350000 | 1269.581100 |
We can also use direct indexing to describe a specific subset of columns:
# For categorical variables
# Define columns we want to select.
cols = ['Fertility Rate', 'Human Development Index']
# Select columns by direct indexing, then describe.
df[cols].describe()
| Fertility Rate | Human Development Index | |
|---|---|---|
| count | 15.000000 | 15.000000 |
| mean | 1.773867 | 0.789333 |
| std | 0.605841 | 0.125514 |
| min | 1.190000 | 0.490000 |
| 25% | 1.366000 | 0.721000 |
| 50% | 1.628000 | 0.842000 |
| 75% | 1.953000 | 0.886500 |
| max | 3.350000 | 0.896000 |
Exercise 6
Write code you need to create a Series that contains the just the means of the Human Development Index, Fertility Rate and Population variables. For good measure, let’s also require that the name attribute is set to mean. The output should look like this:
Human Development Index 0.789333
Fertility Rate 1.773867
Population 236.719867
Name: mean, dtype: float64
Try to do this in as few lines of code as possible, using the methods shown on this page…
# Your code here
Solution to Exercise 6
The output of the .describe() method is itself a Data Frame, and the index of this Data Frame contains a row called mean, which, shockingly, contains the means. As a result, you can use .loc indexing to retrieve just the means from the output of .describe():
# Solution
df.describe().loc['mean']
Human Development Index 0.789333
Fertility Rate 1.773867
Population 236.719867
Name: mean, dtype: float64
Another option is to manually drop the column containing non-numeric data, and then use the .mean() method, and manually specify the name attribute:
mean_series = df.drop(columns='Country Name').mean()
mean_series.name = "mean"
mean_series
Human Development Index 0.789333
Fertility Rate 1.773867
Population 236.719867
Name: mean, dtype: float64
A further solution (much less elegent) is to calculate the means manually, store them in an array or list, then using the pd.Series() constructor with name = mean and index = ['Human Development Index', 'Fertility Rate', 'Population']:
# Calculate the means
mean_hdi = df['Human Development Index'].mean()
mean_fert = df['Fertility Rate'].mean()
mean_pop = df['Population'].mean()
# An array of the means
means_arr = np.array([mean_hdi, mean_fert, mean_pop])
# Create a Series
means_series = pd.Series(means_arr,
name="means",
index= ['Human Development Index',
'Fertility Rate', 'Population'])
means_series
Human Development Index 0.789333
Fertility Rate 1.773867
Population 236.719867
Name: means, dtype: float64
Phew! That really was inefficient. Many Pandas methods are designed to save us time in situations exactly like this…
In fact, Pandas is a particularly good example of a complex library where there are many ways of achieving the same result, and where AI or careless StackOverflow searches can give you a very inefficient or inelegant solution. We strongly advise you to keep investing the time to work out the most elegant solution to your Pandas problems, in order to keep learning, and so that you write code that others can read, including you, the maintainer.
Because each Data Frame column is just a Pandas Series, all of the Series methods we saw above can be used on individual Series:
# Mean of Series extracted from a Data Frame.
df['Fertility Rate'].mean()
np.float64(1.7738666666666667)
By contrast, other methods, like .sort_values() take a column name as an argument, but have effects on the entire Data Frame.
For instance, if we want to sort rows of the whole Data Frame by Human Development Index scores:
# Sort values by HDI, lowest value first (sort ascending).
df_by_hdi = df.sort_values('Human Development Index')
df_by_hdi
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| IND | 0.490 | 3.350 | 1057.9227 | India |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| USA | 0.894 | 2.030 | 281.4841 | United States |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
# Sort values by HDI, highest value first (sort descending).
df_by_hdi_reversed = df.sort_values('Human Development Index',
ascending=False)
df_by_hdi_reversed
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| IND | 0.490 | 3.350 | 1057.9227 | India |
We can also sort the Data Frame rows by the values in the index, using .sort_index(). By default this sorts the Index values from lowest to highest. Because the Index in our case has str values, this sorts the Index in alphabetical order, so df.sort_index() will arrange the rows of the Data Frame in alphabetical order according to the Index values:
# Sort index (in alphabetical order)
df_by_hdi_reversed.sort_index()
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
# Sort index (reverse alphabetical order)
df_rev_ind = df_by_hdi_reversed.sort_index(ascending=False)
df_rev_ind
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| USA | 0.894 | 2.030 | 281.4841 | United States |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
Another useful method that can be powerful in tandem with label-based indexing, is .drop(). This lets us specify rows, using index labels, that we want to remove from the Data Frame. For instance, if we want to remove the data for Australia we can use:
# Drop the 'USA' row
df_rev_ind.drop(index='USA')
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
If you compare this to the output from the last cell you will see that, as if by magic, the row for USA has disappeared.
In addition to removing data from the Dataframe, we will also often want to replace data. Maybe we want to recode categorical data with better labels, create custom dummy/indicator variables, or correct errors etc.
We can replace values using the descriptively named .replace() method. Lets say we want to use the abbreviation UK instead of United Kingdom in the Country Name column. We just give .replace() the value we want to replace, followed by the value we want to replace it with:
# The `.replace()` method applied to a Series (in a Data Frame).
df['Country Name'].replace("United Kingdom", "UK")
Code
AUS Australia
BRA Brazil
CAN Canada
CHN China
DEU Germany
ESP Spain
FRA France
GBR UK
IND India
ITA Italy
JPN Japan
KOR South Korea
MEX Mexico
RUS Russia
USA United States
Name: Country Name, dtype: str
Sure enough, United Kingdom has been replaced with UK in the Series in the output of the cell above. We can also do this with collections of values (e.g. using a dict or list etc) rather than just single values, should we feel moved to do so.
By default, .replace() only replaces values that are equal to the first (target) argument to .replace.
For instance, we might expect the following code to replace United in both United Kingdom and United States, but we would be wrong:
# Not what we want.
df['Country Name'].replace("United", "Disunited")
Code
AUS Australia
BRA Brazil
CAN Canada
CHN China
DEU Germany
ESP Spain
FRA France
GBR United Kingdom
IND India
ITA Italy
JPN Japan
KOR South Korea
MEX Mexico
RUS Russia
USA United States
Name: Country Name, dtype: str
This did not work because .replace() is searching for an element of the
Series which equals United, not that contains United. (There is an
alternative string-specific .replace() method, which behaves differently as
we will see on a later page).
We can achieve the desired result using the regex (standing for “regular expression”) argument:
# Allowing replace on a partial match.
df['Country Name'].replace("United", "Disunited", regex=True)
Code
AUS Australia
BRA Brazil
CAN Canada
CHN China
DEU Germany
ESP Spain
FRA France
GBR Disunited Kingdom
IND India
ITA Italy
JPN Japan
KOR South Korea
MEX Mexico
RUS Russia
USA Disunited States
Name: Country Name, dtype: str
With regex=True, the .replace() method has searched for matches within other strings. So, United has been replaced in both United Kingdom and United States, despite not matching either string in full.
The .replace method can also be used for Series with numeric dtypes. For instance, some particularly patriotic data analyst might want to do the following replacement:
# The Replace method, with numeric data.
df['Human Development Index'].replace(0.894, 100000)
Code
AUS 0.896
BRA 0.668
CAN 0.890
CHN 0.586
DEU 0.890
ESP 0.828
FRA 0.844
GBR 0.863
IND 0.490
ITA 0.842
JPN 0.883
KOR 0.824
MEX 0.709
RUS 0.733
USA 100000.000
Name: Human Development Index, dtype: float64
Methods for getting subsets of data from a Data Frame#
Another common operation we may want to perform is to view only the start (e.g. the .head) or the end (e.g. the .tail) of a Data Frame. For instance, if the rows are organized by time, amongst many other reasons.
We could just use .iloc position-based indexing to do this. For example, to view the first three rows of the Data Frame we can use:
# View the first three rows of the Data Frame, using `.iloc`
df.iloc[:3]
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
Or, alternatively, to view the last three rows:
# View the last three rows of the Data Frame, using `.iloc`
df.iloc[-3:]
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
However, the kind folks at Pandas, because these operations are so common, have provided us the .head() and .tail() methods to do the same thing, with less typing and better readability.
.head() without arguments gives us the first five rows, equivalent to .iloc[5].
# Default .head() gives first five rows.
# Equivalent to `df.iloc[:5]
df.head()
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
We can pass an integer to the .head() method to specify the number of rows from the start of the Data Frame which we want to view.
# Specify number of rows to .head().
# Equivalent to `df.iloc[:3]
df.head(3)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
# View the first three rows of the Data Frame, using `.head()`
df.head(3)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
We can also do the same thing at the other end of the Data Frame, using the .tail() method:
# By default, `.tail()` gives the last five rows of the Data Frame.
# Equivalent to `df.iloc[-5:]
df.tail()
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
# Specify the number of rows counting from the last.
df.tail(3)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
In addition to retrieving rows from the extremes of the Data Frame, we may also, for many different purposes, want to retrieve a random set of rows.
We can do this using the .sample() method. The syntax here is just the same as for .head() and .tail(), only now we are specifying the number of random rows we want to grab from the Data Frame.
For instance, if let’s say we want to get three random rows, without replacement (so that we can’t get the same row twice):
# Grab three rows at random using `.sample()`
df.sample(n=3)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| USA | 0.894 | 2.030 | 281.4841 | United States |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
Even using the small dataset we have here, the overwhelming probability is that we will get a different selection of rows each time we run this command:
# Grab three rows at random AGAIN using `.sample()`
df.sample(n=3)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| USA | 0.894 | 2.030 | 281.4841 | United States |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
If you are running this tutorial interactively, re-run the cell above a few times to see randomness in action…
Check the documentation for .sample by uncommenting the cell below, and running the cell (e.g. with Shift-Return):
# Show documentation with (uncomment below and run):
df.sample?
Notice that by default the sampling is without replacement, so once a row has been pulled into the output sample, it cannot be selected again for the remaining values in the sample. When we deal out hands of cards from a standard 52-card deck., we are sampling from the pack without replacement, because any one card cannot be dealt more than once.
# The first five rows.
first_five = df.head()
# Sample four values without replacement (the default).
first_five.sample(n=4)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
Notice that no row appears twice in the sample. Notice too that if we pass in an n of more than the number of rows, resampling without replacement has to fail, because it will run out of rows to sample from:
# Trying to take a without-replacement sample that is too large.
first_five.sample(n=10)
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[81], line 2
1 # Trying to take a without-replacement sample that is too large.
----> 2 first_five.sample(n=10)
File /opt/hostedtoolcache/Python/3.12.12/x64/lib/python3.12/site-packages/pandas/core/generic.py:6000, in NDFrame.sample(self, n, frac, replace, weights, random_state, axis, ignore_index)
5997 if weights is not None:
5998 weights = sample.preprocess_weights(self, weights, axis)
-> 6000 sampled_indices = sample.sample(obj_len, size, replace, weights, rs)
6001 result = self.take(sampled_indices, axis=axis)
6003 if ignore_index:
File /opt/hostedtoolcache/Python/3.12.12/x64/lib/python3.12/site-packages/pandas/core/sample.py:161, in sample(obj_len, size, replace, weights, random_state)
154 if not replace and size * weights.max() > 1:
155 raise ValueError(
156 "Weighted sampling cannot be achieved with replace=False. Either "
157 "set replace=True or use smaller weights. See the docstring of "
158 "sample for details."
159 )
--> 161 return random_state.choice(obj_len, size=size, replace=replace, p=weights).astype(
162 np.intp, copy=False
163 )
File numpy/random/mtrand.pyx:1025, in numpy.random.mtrand.RandomState.choice()
ValueError: Cannot take a larger sample than population when 'replace=False'
Conversely, if we specify with-replacement sampling, we can ask for as many values as we want.
# Sampling 10 values from original 5, *with replacement*.
first_five.sample(n=10, replace=True)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
We have so far specified the size of our sample with n — the number of rows
in the sample — but we can also specify the size as a fraction of the whole
Data Frame. To get a sample that is half the size the original Data Frame
(np.round(15 / 2) == 8):
# Take sample half the size of the original.
df.sample(frac=0.5)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
Exercise 7
There are functions within Numpy (as well as other libraries) that shuffle/permute/randomize data within an array (or an arraylike object, such as a list).
Let’s say we want to shuffle the rows in our Data Frame. We can do this with the permutation() function from the numpy.random submodule, but the output is very ugly. This operation brutally removes the nice Data Frame graphics (at least when run in a Jupyter notebook), and puts the rows of the Data Frame into a Numpy array, as shown below:
# Effective but ugly
np.random.permutation(df)
array([[0.842, 1.249, 57.2722, 'Italy'],
[0.896, 1.764, 19.1324, 'Australia'],
[0.668, 2.247, 174.0182, 'Brazil'],
[0.844, 1.876, 59.4837, 'France'],
[0.733, 1.19, 146.7177, 'Russia'],
[0.883, 1.346, 127.0278, 'Japan'],
[0.894, 2.03, 281.4841, 'United States'],
[0.824, 1.467, 46.7666, 'South Korea'],
[0.89, 1.51, 30.8918, 'Canada'],
[0.828, 1.21, 41.0197, 'Spain'],
[0.49, 3.35, 1057.9227, 'India'],
[0.863, 1.641, 59.0573, 'United Kingdom'],
[0.89, 1.386, 81.7972, 'Germany'],
[0.709, 2.714, 98.6255, 'Mexico'],
[0.586, 1.628, 1269.5811, 'China']], dtype=object)
Can you think of a way to perform this operation using only the Pandas methods we have seen so far on this page? In the cell below, you should write code which will:
randomize the order of the rows in the Data Frame. The data in each row should be the same as before shuffling (e.g. the data for Russia should still be the data for Russia etc.)
ensure that no rows are removed or duplicated, just shuffled
Try to find the solution in the cell below. Use as few lines of code as possible:
# Your solution here
Solution to Exercise 7
The solution is to take a .sample() which is the same size as the number of rows in the original dataframe. We can do this easily by using n = len(df) as in the input for df.sample():
# A trick to shuffle the rows
df.sample(n=len(df))
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
Or, with greater grace, we can use frac=1, to mean “take a random sample of 100% of the rows”, effectively permuting them:
# A clean, efficient way to permute the rows
df.sample(frac=1)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| JPN | 0.883 | 1.346 | 127.0278 | Japan |
| AUS | 0.896 | 1.764 | 19.1324 | Australia |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CHN | 0.586 | 1.628 | 1269.5811 | China |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| USA | 0.894 | 2.030 | 281.4841 | United States |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| IND | 0.490 | 3.350 | 1057.9227 | India |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| FRA | 0.844 | 1.876 | 59.4837 | France |
If you look at the index of either Data Frame in the above ceels, you’ll notice that the rows are now in a random order.
Because the sample is a random selection of the rows - and the default setting of .sample() is to sample without replacement - using both .sample(len(df)) and df.sample(frac=1) has the effect of randomizing the row order. All the original rows remaining in the sample, and there is no duplication of any rows.
This method is often used on individual columns to (most likely) remove any statistical relationships between the data in that column and other columns. For instance, for permutation testing.
Exercise 8
We mentioned above that the default behaviour of the .sample() method is to sample without replacement. We also mentioned that you can use the replace= argument to sample with replacement.
To use a classic “drawing marbles from a bag” analogy, this means that when we randomly select a marble, we place it back in the bag (after recording it’s identity/colour etc) before we randomly draw the next marble. This means the same marble can appear twice in the final sample.
As mentioned above, if we draw a sample of rows with replacement from our Data Frame, then individual rows can appear more than once in the resultant sample. If we draw a sample with replacement which is larger than the original data, it will certainly contain duplicate rows:
# A sample with replacement
df.sample(len(df) + 10,
replace=True)
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| IND | 0.490 | 3.350 | 1057.9227 | India |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| DEU | 0.890 | 1.386 | 81.7972 | Germany |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| USA | 0.894 | 2.030 | 281.4841 | United States |
| ITA | 0.842 | 1.249 | 57.2722 | Italy |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| USA | 0.894 | 2.030 | 281.4841 | United States |
| FRA | 0.844 | 1.876 | 59.4837 | France |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| CAN | 0.890 | 1.510 | 30.8918 | Canada |
| ESP | 0.828 | 1.210 | 41.0197 | Spain |
| RUS | 0.733 | 1.190 | 146.7177 | Russia |
| USA | 0.894 | 2.030 | 281.4841 | United States |
Quickly scan the index for duplicates, to see that it contains duplicates (as it must, in order to generate a sample of this size).
Your task is the following:
take a random sample with replacement of all the rows in the Data Frame (e.g. your sample should have the same number of rows as the original Data Frame)
use an appropriate method to calculate the means of
Human Development Index,Fertility RateandPopulation, from your random sampleusing Pandas methods and indexing operations, calculate the difference between the means of
Human Development Index,Fertility RateandPopulationin your sample vs the means for the same variables in the original datastore your result in a Pandas Series (note: depending what methods you use, your result may automatically be stored in a Pandas Series)
The result should look something like this (though your differences will differ from the ones shown below, because of the randomness inherent in your sampling):
Human Development Index 0.074467
Fertility Rate -0.182600
Population -210.516580
Name: mean, dtype: float64
Try to do this in as few lines of code as possible.
# Your code here
Solution to Exercise 8
There are several ways you can achieve this, but one way of doing it in a single line of code is to chain Pandas methods together.
The left hand side of the subtraction operation in the cell below uses the .describe() method and .loc indexing to calculate the means of the original data.
The right hand side of the subtraction draws a sample (the same size as the number of rows in df) using .sample() with replace=True. It then uses .describe() to calculate the means of the numeric variables in this random sample, and then .loc to select just those means (as opposed to including the other information that .describe() reports, like standard deviations etc).
The result of this subtraction shows us the difference between the original means and the means of our resample (e.g. our random sample, drawn with replacement):
# Show the difference in the means (original data vs resample)
df.describe().loc['mean'] - df.sample(len(df), replace=True).describe().loc['mean']
Human Development Index -0.041000
Fertility Rate 0.225067
Population 94.614347
Name: mean, dtype: float64
You can also perform the same process, less efficiently, spread over multiple lines of code. The way shown below is not the only possible way - perhaps you used the .mean() method individually on each column, for instance, and then manually constructed a Series to store the results (even less efficient!) . Alternatively, you might have used .drop() to remove non-numeric columns, and then used .mean() in parallel on the numeric columns, another valid approach:
# Calculate the original means
original_means = df.describe().loc['mean']
# Generate a resample
resample = df.sample(len(df),
replace=True)
# Calculate the resample means
resample_means = resample.describe().loc['mean']
# Calculate the difference in means
difference_in_means = original_means - resample_means
# Show the difference
difference_in_means
Human Development Index 0.051533
Fertility Rate 0.108267
Population -182.270607
Name: mean, dtype: float64
Similar kinds of resampling procedure are often used to generate bootstrapped confidence intervals.
Plotting Methods#
The Data Frame plotting methods that we have seen on the previous pages also apply to Series.
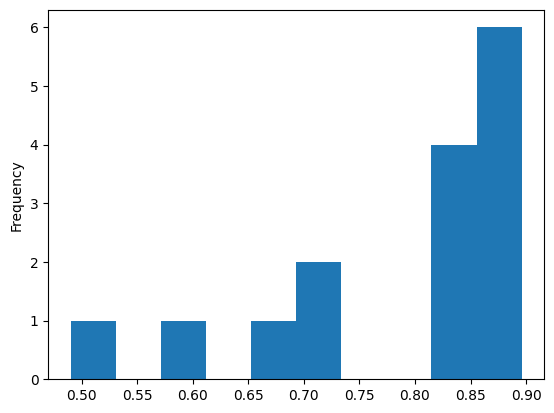
When working with a Series, it makes most sense most of the time to use the
kind='hist' argument to inspect the distribution of the data in that Series:
hdi_series.plot(kind='hist');
Other kinds of plot require data specified both for the x- and y- axes, so can only be used with Data Frames:
# A ValueError from trying to scatter plot a Series
hdi_series.plot(kind='scatter')
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
Cell In[93], line 2
1 # A ValueError from trying to scatter plot a Series
----> 2 hdi_series.plot(kind='scatter')
File /opt/hostedtoolcache/Python/3.12.12/x64/lib/python3.12/site-packages/pandas/plotting/_core.py:1131, in PlotAccessor.__call__(self, *args, **kwargs)
1129 return plot_backend.plot(data, x=x, y=y, kind=kind, **kwargs)
1130 else:
-> 1131 raise ValueError(f"plot kind {kind} can only be used for data frames")
1132 elif kind in self._series_kinds:
1133 if isinstance(data, ABCDataFrame):
ValueError: plot kind scatter can only be used for data frames
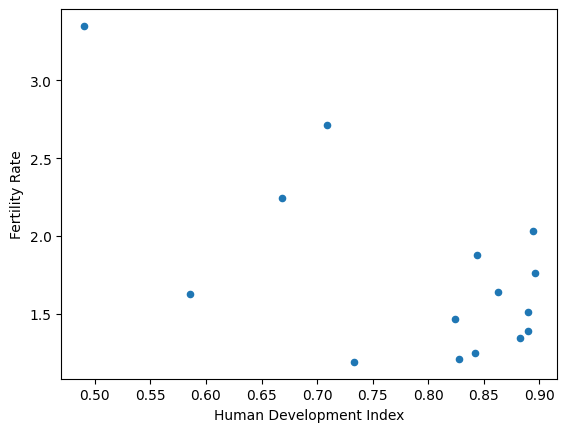
# Show a scatter plot on a Data Frame, specifying x- and y- axes.
df.plot(x='Human Development Index',
y='Fertility Rate',
kind='scatter');
A note on numerical operations#
Any numerical operations performed on the Data Frame as a whole will be default be performed on the values in the Series that make up each column.
So, if we want to do something like multiplying the entire Data Frame by a single number, this operation will be performed separately on each element of each Series in the Data Frame.
This might make sense for some Data Frames, but in our case, we have string data in one column, so applying the multiplication to values in the str Series will give us results we probably didn’t want:
# This probably won't make sense in our case.
df * 200
| Human Development Index | Fertility Rate | Population | Country Name | |
|---|---|---|---|---|
| Code | ||||
| AUS | 179.2 | 352.8 | 3826.48 | AustraliaAustraliaAustraliaAustraliaAustraliaA... |
| BRA | 133.6 | 449.4 | 34803.64 | BrazilBrazilBrazilBrazilBrazilBrazilBrazilBraz... |
| CAN | 178.0 | 302.0 | 6178.36 | CanadaCanadaCanadaCanadaCanadaCanadaCanadaCana... |
| CHN | 117.2 | 325.6 | 253916.22 | ChinaChinaChinaChinaChinaChinaChinaChinaChinaC... |
| DEU | 178.0 | 277.2 | 16359.44 | GermanyGermanyGermanyGermanyGermanyGermanyGerm... |
| ESP | 165.6 | 242.0 | 8203.94 | SpainSpainSpainSpainSpainSpainSpainSpainSpainS... |
| FRA | 168.8 | 375.2 | 11896.74 | FranceFranceFranceFranceFranceFranceFranceFran... |
| GBR | 172.6 | 328.2 | 11811.46 | United KingdomUnited KingdomUnited KingdomUnit... |
| IND | 98.0 | 670.0 | 211584.54 | IndiaIndiaIndiaIndiaIndiaIndiaIndiaIndiaIndiaI... |
| ITA | 168.4 | 249.8 | 11454.44 | ItalyItalyItalyItalyItalyItalyItalyItalyItalyI... |
| JPN | 176.6 | 269.2 | 25405.56 | JapanJapanJapanJapanJapanJapanJapanJapanJapanJ... |
| KOR | 164.8 | 293.4 | 9353.32 | South KoreaSouth KoreaSouth KoreaSouth KoreaSo... |
| MEX | 141.8 | 542.8 | 19725.10 | MexicoMexicoMexicoMexicoMexicoMexicoMexicoMexi... |
| RUS | 146.6 | 238.0 | 29343.54 | RussiaRussiaRussiaRussiaRussiaRussiaRussiaRuss... |
| USA | 178.8 | 406.0 | 56296.82 | United StatesUnited StatesUnited StatesUnited ... |
More sensibly, we will most likely want to perform numerical operations on specific columns. We may want to standardize the values relative to a mean of 0 and standard deviation of 1, for instance.
Note
Standard scores
If we have a sequence of values, we can calculate corresponding scores for that sequence by first subtracting the mean of the sequence, and second, dividing the result by the standard deviation of the original sequence.
The result is the standard score of each element in the sequence.
The process of calculating standard scores can be called standardization. Standard scores are sometimes called z-scores.
Pandas methods can be used to perform this computation, and again, the operation will be performed on each element in the values array of the specific Series/column that we grab.
For instance, to subtract the mean value from every element in the .values array we can use:
# Subtract the mean from every element in the Series
df['Population'] - df['Population'].mean()
Code
AUS -217.587467
BRA -62.701667
CAN -205.828067
CHN 1032.861233
DEU -154.922667
ESP -195.700167
FRA -177.236167
GBR -177.662567
IND 821.202833
ITA -179.447667
JPN -109.692067
KOR -189.953267
MEX -138.094367
RUS -90.002167
USA 44.764233
Name: Population, dtype: float64
We can perform the full z-score standardization using the code in the cell below. Note that df['Population'].mean() and df['Population'].std() both return single values. Each of these values is used in the same way on every element in the Population column:
# Standardize the `Population` scores
df['Population_z'] = ((df['Population'] - df['Population'].mean())
/ df['Population'].std())
df
| Human Development Index | Fertility Rate | Population | Country Name | Population_z | |
|---|---|---|---|---|---|
| Code | |||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia | -0.565922 |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil | -0.163080 |
| CAN | 0.890 | 1.510 | 30.8918 | Canada | -0.535337 |
| CHN | 0.586 | 1.628 | 1269.5811 | China | 2.686362 |
| DEU | 0.890 | 1.386 | 81.7972 | Germany | -0.402937 |
| ESP | 0.828 | 1.210 | 41.0197 | Spain | -0.508995 |
| FRA | 0.844 | 1.876 | 59.4837 | France | -0.460972 |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom | -0.462081 |
| IND | 0.490 | 3.350 | 1057.9227 | India | 2.135861 |
| ITA | 0.842 | 1.249 | 57.2722 | Italy | -0.466724 |
| JPN | 0.883 | 1.346 | 127.0278 | Japan | -0.285297 |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea | -0.494048 |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico | -0.359169 |
| RUS | 0.733 | 1.190 | 146.7177 | Russia | -0.234086 |
| USA | 0.894 | 2.030 | 281.4841 | United States | 0.116427 |
Because this feature (numerical operations performed on each element) is shared across all Pandas Series, and we are using Pandas methods, we can write a function which will compute the z-scores for any column containing numerical data:
# Define a function to calculate standard scores for a numeric Series.
def get_standard(in_series):
""" Returns Series with standard score of each element of `in_series`.
"""
# Formula for standard score.
return (in_series - in_series.mean()) / in_series.std()
# test our function
get_standard(df['Human Development Index'])
Code
AUS 0.849838
BRA -0.966690
CAN 0.802034
CHN -1.620003
DEU 0.802034
ESP 0.308066
FRA 0.435542
GBR 0.586919
IND -2.384857
ITA 0.419607
JPN 0.746264
KOR 0.276197
MEX -0.640034
RUS -0.448820
USA 0.833903
Name: Human Development Index, dtype: float64
Again, each numerical operation that the function performs has been performed on every element of the .values array of the Data Frame column Human Development Index.
Let’s add these new standardized data to the Data Frame, and plot them using the now familiar .plot() method:
# Add standard scores for HDI
df['HDI_z'] = get_standard(df['Human Development Index'])
df
| Human Development Index | Fertility Rate | Population | Country Name | Population_z | HDI_z | |
|---|---|---|---|---|---|---|
| Code | ||||||
| AUS | 0.896 | 1.764 | 19.1324 | Australia | -0.565922 | 0.849838 |
| BRA | 0.668 | 2.247 | 174.0182 | Brazil | -0.163080 | -0.966690 |
| CAN | 0.890 | 1.510 | 30.8918 | Canada | -0.535337 | 0.802034 |
| CHN | 0.586 | 1.628 | 1269.5811 | China | 2.686362 | -1.620003 |
| DEU | 0.890 | 1.386 | 81.7972 | Germany | -0.402937 | 0.802034 |
| ESP | 0.828 | 1.210 | 41.0197 | Spain | -0.508995 | 0.308066 |
| FRA | 0.844 | 1.876 | 59.4837 | France | -0.460972 | 0.435542 |
| GBR | 0.863 | 1.641 | 59.0573 | United Kingdom | -0.462081 | 0.586919 |
| IND | 0.490 | 3.350 | 1057.9227 | India | 2.135861 | -2.384857 |
| ITA | 0.842 | 1.249 | 57.2722 | Italy | -0.466724 | 0.419607 |
| JPN | 0.883 | 1.346 | 127.0278 | Japan | -0.285297 | 0.746264 |
| KOR | 0.824 | 1.467 | 46.7666 | South Korea | -0.494048 | 0.276197 |
| MEX | 0.709 | 2.714 | 98.6255 | Mexico | -0.359169 | -0.640034 |
| RUS | 0.733 | 1.190 | 146.7177 | Russia | -0.234086 | -0.448820 |
| USA | 0.894 | 2.030 | 281.4841 | United States | 0.116427 | 0.833903 |
# Plot the standardized variables.
# Notice both range from negative to positive.
df.plot(kind='scatter',
x='Population_z',
y='HDI_z');
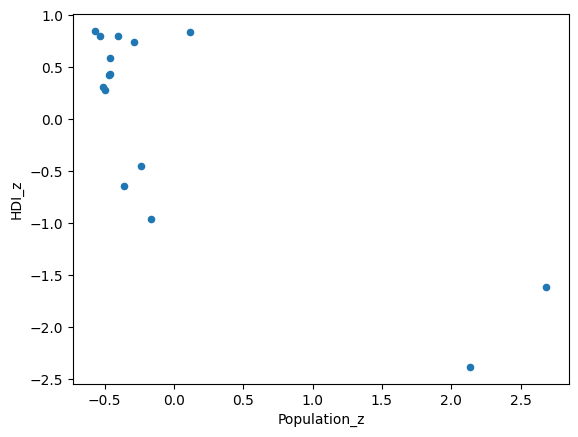
We can see from this procedure that we have two bivariate outliers, with respect to Population and HDI, at the bottom right of the scatter plot.
This dataset is small enough that we can see that these values correspond to India and China…
# Inspect the `Population_z` column to identify the outliers
df['Population_z'].sort_values()
Code
AUS -0.565922
CAN -0.535337
ESP -0.508995
KOR -0.494048
ITA -0.466724
GBR -0.462081
FRA -0.460972
DEU -0.402937
MEX -0.359169
JPN -0.285297
RUS -0.234086
BRA -0.163080
USA 0.116427
IND 2.135861
CHN 2.686362
Name: Population_z, dtype: float64
… but for a larger dataset we could find them using Boolean filtering .
Exercise 9
If you use .plot(kind="bar") you will generate a bar plot (that is, a chart with bars representing counts for different categories).
Your task is to use indexing methods of your choice, restricting yourself to the Pandas methods shown on this page, to create a bar plot which has:
the name of each country on the x-axis
…and…
bars which show the population of the country on the y-axis. The bars should be ordered from highest population (left hand side of the graph) to lowest population (right hand side of the graph).
Unless you enjoy cheating, do not use other plotting libraries!. Your final result should look like this:
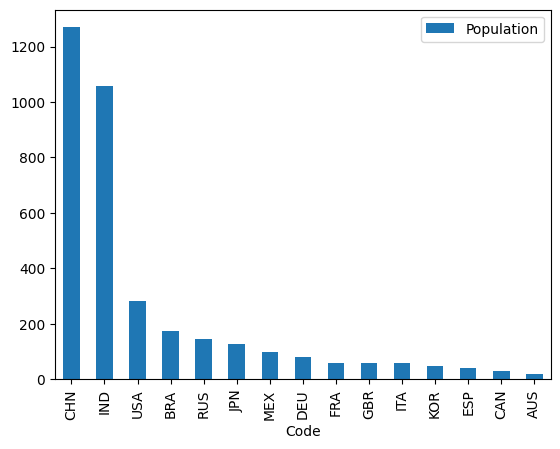
As ever, use as few lines as you can, while but keep your code readable.
# Your code below
Solution to Exercise 9
It is possible to create this plot in one line of code, again, by chaining Pandas methods together. First, we use direct indexing with the column names to select just those variables.
Then we use sort_values() using the by='Population' and ascending=False arguments to ensure that the population counts are sorted in descending order.
We then chain .plot(kind='bar') on the end, and we get the desired plot:
# Solution
df[['Country Name', 'Population']].sort_values(by='Population', ascending=False).plot(kind='bar')
<Axes: xlabel='Code'>
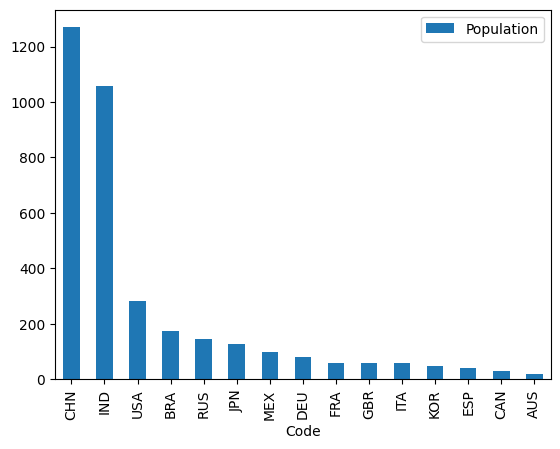
Food for thought: what will happen if you reverse the order of Country Name and Population in the direct indexing operation? Do you think this will change the x-axis and and y-axis variables on the .plot()?
Have a think about what you think will happen; you can check by uncommenting the code below to see if you were correct:
# df[['Population', 'Country Name',]].sort_values(by='Population', ascending=False).plot(kind='bar')
How would you explain the result?
Summary#
On this page we have further explored the idea that Pandas Data Frames, Pandas Series and Numpy arrays have a nested structure.
Data Frames are dictionary-like collections of Series. Series are a combination of a Numpy array (.values) with other attributes (name and index). As a result, many methods we can use on a Series are similar to those available from Numpy arrays, and many Data Frame methods likewise parallel those from the Pandas Series that constitute the Data Frame.